

A Fujitsu Laboratories of Europe bemutatta az elektronikus egészségügyi adatok (EHR) kezelését és a strukturálatlan (szabadszöveges) orvosi feljegyzések feldolgozását automatizáló megoldását.
Az új MI-technológia a nagyobb pontosságának köszönhetően több mint 90%-kal mérsékli a folyamathoz szükséges időt. A kötelező egészségügyi osztályozásoknak megfelelő, új automatikus kódolási megoldás jellemzően kevesebb mint 1 perc alatt kivonatolja a feljegyzéseket, szemben a manuális klinikai feldolgozás 15 perces időigényével. A korábbi megoldásokkal ellentétben a Fujitsu MI-alapú szövegbányászati technológiája a szemantikai tudást természetes nyelvfeldolgozással (Natural Language Processing, NLP) és mélytanulási képességekkel ötvözve elemzi az orvosi feljegyzéseket és kivonatolja a fontos adatokat.
A Fujitsu Laboratories of Europe több innovációs partnerrel – köztük Madrid vezető egészségügyi intézményével, a San Carlos klinikai kórházzal – bonyolított le sikeres klinikai projekteket az elmúlt 4 évben. A kórház orvosigazgatója, dr. Julio Mayol, szakmai szempontból így magyarázza a Fujitsu által alkalmazott „co-creation” szemlélet jelentőségét: „Folyamatosan keressük a klinikai döntéshozás továbbfejlesztésére alkalmas, új módszereket. A Fujitsu Laboratories of Europe-pal folytatott közös munka lehetővé teszi, hogy fontos fejlesztéseket vegyünk igénybe a hatékonyság javítására. A ma elérhető elektronikus egészségügyi adatfeldolgozó rendszerek többsége nem elégíti ki az orvos-beteg kapcsolat követelményeit. Sőt, az ilyen rendszerek használatát több vizsgálat is közvetlen összefüggésbe hozta a klinikai dolgozók kiégésének jelenségével. A Fujitsu új MI-alapú szövegbányászati technológiája segítségével közvetlenül tudjuk kezelni ezt a problémát, és kézzelfogható javulást érhetünk el a klinikai döntéshozási folyamat hatékonyságában.”
A Fujitsu Laboratories of Europe vezérigazgatója, dr. Adel Rouz, így folytatja: „A San Carlos klinikai kórházhoz hasonló partnerek esetében követett co-creation stratégia lehetővé tette, hogy betekintsünk az egészségügyi ágazat kihívásaiba, különös tekintettel a klinikai döntéshozás nehézségeire. Több olyan fontos innovációval is sikerült előállnunk, amelyek megváltoztatják az egészségügyi személyzet által követett munkafolyamatot. Ez újabb lépést jelent a klinikai adatok pontosságának növelése és digitalizálásuk automatizálása felé a kórházak, az egészségbiztosító társaságok és a kormányzati szervek számára. Úgy gondoljuk, hogy technológiánk szélesebb körben is alkalmazható, és más területek (pl. biztosítás, jog vagy megfelelés) hasonló kihívásainak legyőzésére is jól adaptálható.”
A strukturált információk kulcsszerepet játszanak az orvosi döntéshozásban és az egészségügyi ellátás színvonalának javításában. A klinikai szakembereknek azonban egyre kevesebb idejük van a betegekkel foglalkozni, és terhelésüket tovább fokozza, hogy az adatokat kötelesek azonnal bevinni az elektronikus adatkezelő rendszerekbe. A rugalmasabb adatbeviteli módszerek (pl. a betegekről készített jelentések szabadszöveges narratívája) csökkentik az időigényt, és hasznosabb, relevánsabb betegadatok rögzítését teszik lehetővé. A Fujitsu Laboratories és a Fujitsu Laboratories of Europe közös megoldásának bevált természetes nyelvfeldolgozási technikái közvetlenül reagálnak erre a szükségletre azzal, hogy automatikusan kivonatolják az adatfeldolgozó rendszerek számára szükséges strukturált információt a klinikai személyzet beszámolóiból. A szakemberek egyéni igényeire mélytanulási technikával felkészíthető megoldás a más kódoló rendszerek által alkalmazott komplex nyelvészeti szabályokhoz képest nagyobb rugalmasságot nyújt a szabad szöveg megfelelő kifejezéseinek azonosításához. Ebből eredően nagyfokú pontosságot biztosít, és a kezelés megfelelőségére vagy a beteg társadalmi hátterére vonatkozóan többféle kifejezést képes kivonatolni, mint ami a betegségek és az egészséggel kapcsolatos problémák nemzetközi statisztikai osztályozásában (ICD) szerepel.
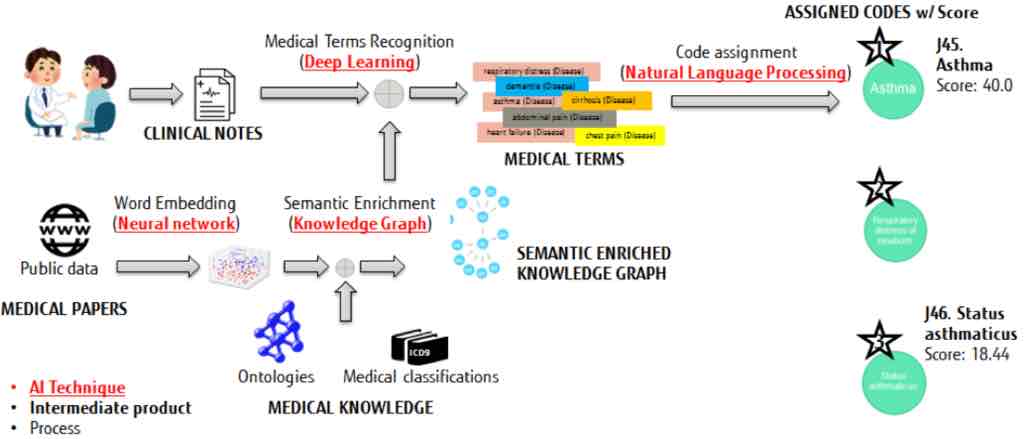
A Fujitsu MI-alapú megoldása a szövegbányászatot mélytanulási technikákkal ötvözi az egészségügyi kódolási munkafolyamat konkrét lépései során, így nem igényel előre feldolgozott óriási adatsorokat a működéshez. A Fujitsu megoldásának két fő komponense:
• tudásbázis létrehozása: a rendszer tudásgráfot alakít ki az egészségügyi osztályozások leképezéséhez, amelyeket szemantikailag külső forrásokkal is kiegészít. A szemantikai kiegészítés további kontextust biztosít az egészségügyi osztályozásokhoz, ami a folyamat egymást követő szakaszai során jobb eredmények elérését teszi lehetővé. A szemantikai kiegészítés eszközei között ontológiák és szóbeágyazási technikák is szerepelnek.
• felismerés és hozzárendelés: az orvosi kifejezések mélytanulásra épülő felismerési folyamata, ami után a rendszer súlyozott pontszámok szerint rangsorolt képletek definiálásával kiszámítja a bevitt klinikai jegyzetek potenciális kódolását.